After giving it some thought, I am going to normalize all the clean signals to -10LUFS and run the listening test at 80dbA as suggested in ITU-R BS 1770 -3
I will then have listeners change the level of a distorted file, to be the same.
This is a similar format to what the ITU did when testing LUFS for multichannel comparability.
It will also mean data can be compared fairly.
If we and LUFS are correct, the listeners should choose a level where the LUFS of the distorted signal is negligible to that of the audio signal.
I will then have listeners change the level of a distorted file, to be the same.
This is a similar format to what the ITU did when testing LUFS for multichannel comparability.
It will also mean data can be compared fairly.
If we and LUFS are correct, the listeners should choose a level where the LUFS of the distorted signal is negligible to that of the audio signal.
A less distorted signal will be boosted more and a more distorted signal will be boosted less.
There is good evidence that LUFS is good stuff, when looking at :
Therefore, we can compare level coefficients to correlation, THD, crest factor, harmonic content, dynamic range and LUFS.
Even if the listener boosts the level of the distorted signal beyond the level of the clean signal, this will show that there is an effect on perceived loudness.
There is good evidence that LUFS is good stuff, when looking at :
The Effect of Dynamic Range Compression on Loudness and Quality Perception in Relation to Crest Factor
This not only suggests that LUFS is pretty accurate, but that a change in crest factor using dynamic range compression will effect loudness perceptionTherefore, we can compare level coefficients to correlation, THD, crest factor, harmonic content, dynamic range and LUFS.
Even if the listener boosts the level of the distorted signal beyond the level of the clean signal, this will show that there is an effect on perceived loudness.
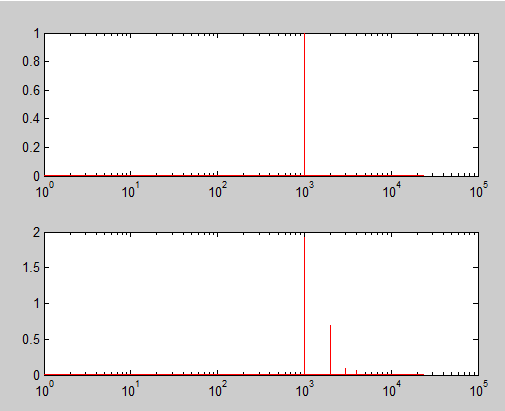
I am going to wittle down the levels of the clipper to reduce the THD caused to a 1kHz sine wave to roughly 0 - 20% THD. This is because beyond this level, the distortion is very audible and I want to minimize the subjective effects of distortion on results. 20% THD is audible enough as it is. A further study could look at those levels of THD. Other studies previously referenced have proven that distortion becomes audible beyond 15% THD, when compared with the effects of clipping on a pure tone.
This will also allow me to slip the signals through other nonlinearities which function with frequency, and see how the different harmonic patterns compare.
I need to learn how to make waterfall plots for these signals. Maybe spectrographs will have to do?
This will also allow me to slip the signals through other nonlinearities which function with frequency, and see how the different harmonic patterns compare.
I need to learn how to make waterfall plots for these signals. Maybe spectrographs will have to do?
Anyway.